Toda empresa que pensa em IA chega num mesmo problema: o ChatGPT é genérico. Ele sabe muito sobre o mundo, e nada sobre o seu catálogo de produtos, sua política de troca, seu contrato modelo, ou o histórico do cliente que ligou agora. Pra ser útil de verdade no dia a dia da empresa, a IA precisa consultar os dados da sua casa antes de responder.
A técnica que faz isso se chama RAG. É um nome técnico, mas a ideia é simples — e entender ela é o que separa quem contrata IA com critério de quem paga por algo que vai falhar em 6 meses.
O problema que RAG resolve
Modelo de linguagem (Claude, GPT, Gemini) é treinado em milhões de textos da internet até uma data. Depois disso, ele não aprende mais nada — está congelado no tempo. E ele nunca leu o conteúdo interno da sua empresa.
Isso cria três problemas práticos quando você usa IA pura no atendimento:
1. Ele inventa informação (“alucina”). Pergunta o preço do seu produto, e ele inventa um número plausível. Pergunta a política de troca, e ele cria uma baseada em “como costuma ser” no setor. Tudo dito com a maior segurança.
2. Ele desatualiza rápido. Mesmo que você “treine” o modelo com seus dados, no dia que mudar o preço ou lançar produto novo, ele continua respondendo o antigo.
3. Ele não cita fonte. Pra atendimento de venda ou suporte, isso é grave — uma resposta errada vira problema legal ou cliente insatisfeito.
RAG resolve os três problemas de uma vez.
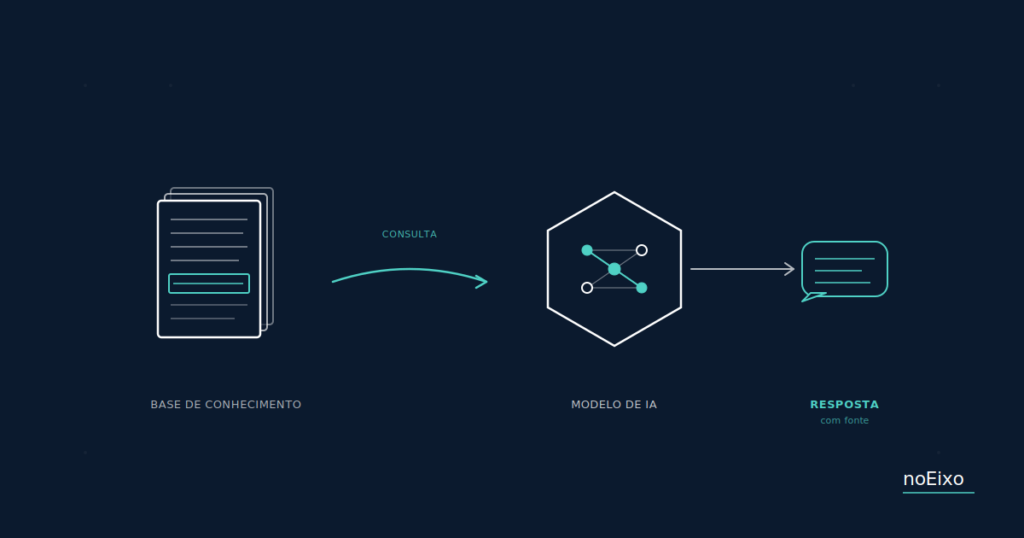
O que RAG faz, na prática
A sigla significa Retrieval-Augmented Generation. Traduzindo livre: “geração com busca embutida”.
A imagem mental mais útil é uma biblioteca com bibliotecário e redator:
- A biblioteca é o conjunto de documentos da sua empresa: catálogo, FAQ, manual, política, base de produtos, histórico de cliente, contratos.
- O bibliotecário é o sistema que, a cada pergunta do cliente, procura os trechos mais relevantes na biblioteca. Em milissegundos.
- O redator é o modelo de IA, que recebe a pergunta original do cliente junto com os trechos que o bibliotecário trouxe, e redige uma resposta baseada exclusivamente naqueles trechos.
O resultado: a IA responde com a informação real da sua empresa, atualizada, com fonte verificável. E quando não tem informação na biblioteca pra responder, ela diz “não sei” em vez de inventar.
O fluxo, passo a passo
- Cliente pergunta: “Vocês fazem entrega na zona sul de Floripa?”
- O sistema transforma a pergunta em uma representação matemática (embedding) — captura o “significado” da pergunta em números.
- Busca, na biblioteca, os trechos mais próximos desse significado. Encontra: política de entrega, lista de bairros, tempo médio por região.
- Monta um prompt pro modelo: “Com base nas informações a seguir, responda à pergunta do cliente. Se não tiver a resposta nas informações, diga que não sabe.”
- Modelo gera a resposta consultando aqueles trechos: “Sim, atendemos a zona sul. O prazo médio pra bairros como Carianos e Campeche é 48h.”
Tudo em 1–3 segundos. Sem alucinação. Com fonte rastreável.
Que tipo de documento entra na biblioteca
Quase tudo que sua empresa já tem em texto pode virar fonte:
- Catálogo de produtos e serviços com descrição, preço, especificação
- FAQ (perguntas frequentes que cliente faz)
- Política de troca, entrega, garantia, cancelamento
- Manuais de produto ou guia de uso
- Base de conhecimento interna (procedimentos, padrões, regras)
- Contratos modelo
- Histórico de atendimento
- Planilhas estruturadas (lista de preços, tabela de prazos, regras por região)
O que não entra: dados que mudam segundo a segundo (estoque em tempo real), conteúdo desatualizado (RAG não “limpa” sozinho — se entra coisa errada, sai resposta errada).
Onde RAG falha (e quase ninguém fala isso)
Análises de produção em 2026 mostram que sistemas RAG falham na etapa de busca (não na geração) em cerca de 73% dos casos problemáticos. Os três motivos clássicos:
1. Fragmentação ruim dos documentos (chunking). A biblioteca precisa quebrar documentos longos em pedaços pequenos. Se o pedaço corta uma frase no meio, mistura assuntos, ou separa contexto importante, o bibliotecário busca mal.
2. Vocabulário diferente entre pergunta e documento. Cliente pergunta “como cancelo minha conta?”. Documento da empresa fala em “rescisão contratual”. O bibliotecário pode não fazer a ponte.
3. Biblioteca contaminada com lixo. Se você joga 500 PDFs antigos na biblioteca, com versões conflitantes da mesma política, a IA vai responder confundindo as duas.
Como saber se o fornecedor entende RAG de verdade
1. “Como vocês fragmentam os documentos? Por tamanho fixo, semanticamente ou por estrutura?” “Tamanho fixo, 500 caracteres” = básico, falha em documentos complexos. “Semântica, com sobreposição entre chunks, mantendo metadados de seção” = sério.
2. “Vocês usam busca semântica, palavra-chave ou híbrida?” Só semântica = falha quando cliente usa termo exato. Só palavra-chave = falha quando cliente pergunta com palavras diferentes. Híbrida = boa engenharia.
3. “Como o sistema sabe quando não tem a resposta?” “Ele sempre tenta responder” = perigo, vai alucinar. “Se a confiança da busca é baixa, ele diz que não tem informação e transfere pra humano” = correto.
4. “Posso ver quais documentos a IA consultou pra dar uma resposta específica?” “Não dá pra ver” = caixa preta, evita. “Sim, cada resposta vem com referência aos trechos consultados” = sistema observável e auditável.
Custo e prazo realistas
- Curadoria e estruturação da base de conhecimento: 40–50% do esforço total. É aqui que mora a qualidade.
- Configuração técnica: 20–30% (modelo de embedding, banco vetorial, estratégia de busca).
- Integração com canais e sistemas externos: 15–25%.
- Testes, ajustes e monitoramento: 10–15%, e isso continua depois do lançamento.
Em projetos reais de PME, RAG decente entre R$ 8.000 e R$ 25.000 de implementação, mais R$ 400–1.500/mês de operação.
Perguntas frequentes
RAG é a mesma coisa que treinar uma IA com meus dados? Não. Treinar (fine-tuning) ensina um estilo ou conhecimento permanente ao modelo — é caro, lento e difícil de atualizar. RAG mantém o modelo intacto e consulta dados externos no momento da pergunta — é mais barato, atualiza fácil, e permite citar fonte.
Meus dados ficam armazenados em servidor da OpenAI/Anthropic/Google? Depende de como o sistema é construído. Em RAG bem desenhado, sua biblioteca fica em servidor controlado por você, e só os trechos relevantes passam pelo modelo. Provedores empresariais não usam esses trechos pra treinar.
Funciona em português? Funciona. Há modelos de embedding multilíngues maduros e modelos geradores excelentes em português (Claude, GPT-4o, Gemini). Atenção: alguns modelos open-source pequenos têm performance ruim em português.
Quando chamar a noEixo Digital
Estruturar base de conhecimento e implementar RAG bem feito é uma das especialidades da noEixo. Trabalhamos o ciclo completo: levantamento e curadoria do conteúdo, escolha de modelos e infraestrutura, configuração da busca, integração com WhatsApp Business API e os sistemas que você já usa.
Agenda um diagnóstico gratuito em noeixodigital.com — em 30–45 minutos analisamos que tipo de base você tem hoje e qual o caminho mais direto pra colocar IA com seus dados rodando.